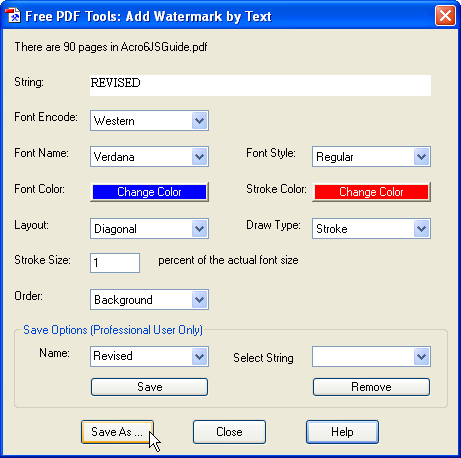
Default Encoding Of Pdf
Character encoding Wikipedia. In computing character encoding is used to represent a repertoire of characters by some kind of encoding system. Depending on the abstraction level and context, corresponding code points and the resulting code space may be regarded as bit patterns, octets, natural numbers, electrical pulses, etc. A character encoding is used in computation, data storage, and transmission of textual data. Character set, character map, codeset and code page are related, but not identical, terms. Early character codes associated with the optical or electrical telegraph could only represent a subset of the characters used in written languages, sometimes restricted to upper case letters, numerals and some punctuation only. The low cost of digital representation of data in modern computer systems allows more elaborate character codes such as Unicode which represent most of the characters used in many written languages. Character encoding using internationally accepted standards permits worldwide interchange of text in electronic form. HistoryeditEarly binary repertoires include Bacons cipher, Braille, International maritime signal flags, and the 4 digit encoding of Chinese characters for a Chinese telegraph code Hans Schjellerup, 1. Common examples of character encoding systems include Morse code, the Baudot code, the American Standard Code for Information Interchange ASCII and Unicode. Morse code was introduced in the 1. Latin alphabet, each Arabic numeral, and some other characters via a series of long and short presses of a telegraph key. Representations of characters encoded using Morse code varied in length. The Baudot code, a five bit encoding, was created by mile Baudot in 1. Donald Murray in 1. CCITT as International Telegraph Alphabet No. ITA2 in 1. 93. 0. Fieldata, a six or seven bit code, was introduced by the U. S. Army Signal Corps in the late 1. IBMs Binary Coded Decimal BCD was a six bit encoding scheme used by IBM in as early as 1. Series for example, 7. One example of a plugin would be a PDF viewer that is instantiated in a browsing context when the user navigates to a PDF file. This would count as a plugin. Convert text to PDF optimized for ebook readers with this free online ebook converter. Select target devices like the Kindle or Sony reader to enhance formatting. Set the Default PDF Viewer in Mac OS X Back to Preview. BCD extended existing simple four bit numeric encoding to include alphabetic and special characters, mapping it easily to punch card encoding which was already in widespread use. It was the precursor to EBCDIC. ASCII was introduced in 1. IBMs Extended Binary Coded Decimal Interchange Code usually abbreviated as EBCDIC is an eight bit encoding scheme developed in 1. The limitations of such sets soon became apparent, and a number of ad hoc methods were developed to extend them. The need to support more writing systems for different languages, including the CJK family of East Asian scripts, required support for a far larger number of characters and demanded a systematic approach to character encoding rather than the previous ad hoc approaches. HTML5. A vocabulary and associated APIs for HTML and XHTML. W3C Recommendation 28 October 2014. Geospatial PDF Available for GDAL 1. GDAL supports reading Geospatial PDF documents, by extracting georeferencing information and rasterizing the data. Encoding Conversion Data encoding compatibility problems are one of the most common difficulties. Adobe is changing the world through digital experiences. We help our customers create, deliver and optimize content and applications. In trying to develop universally interchangeable character encodings, researchers in the 1. Latin alphabet who still constituted the majority of computer users, those additional bits were a colossal waste of then scarce and expensive computing resources as they would always be zeroed out for such users. The compromise solution that was eventually found and developed into Unicode was to break the assumption dating back to telegraph codes that each character should always directly correspond to a particular sequence of bits. Instead, characters would first be mapped to a universal intermediate representation in the form of abstract numbers called code points. Code points would then be represented in a variety of ways and with various default numbers of bits per character code units depending on context. To encode code points higher than the length of the code unit, such as above 2. TerminologyeditTerminology related to code unit A character is a minimal unit of text that has semantic value. A character set is a collection of characters that might be used by multiple languages. Example The Latin character set is used by English and most European languages, though the Greek character set is used only by the Greek language. A coded character set is a character set in which each character corresponds to a unique number. A code point of a coded character set is any allowed value in the character set. A code unit is a bit sequence used to encode each character of a repertoire within a given encoding form. Character repertoire the abstract set of charactersThe character repertoire is an abstract set of more than one million characters found in a wide variety of scripts including Latin, Cyrillic, Chinese, Korean, Japanese, Hebrew, and Aramaic. Other symbols such as musical notation are also included in the character repertoire. Both the Unicode and GB1. As new characters are added to one standard, the other standard also adds those characters, to maintain parity. The code unit size is equivalent to the bit measurement for the particular encoding A code unit in US ASCII consists of 7 bits A code unit in UTF 8, EBCDIC and GB1. A code unit in UTF 1. A code unit in UTF 3. Example of a code unit Consider a string of the letters abc followed by U1. DESERET CAPITAL LETTER LONG I represented with 1 char. That string contains four characters four code pointseither. UTF 3. 2 0. 00. UTF 1. UTF 8 6. 1, 6. 2, 6. To express a character in Unicode, the hexadecimal value is prefixed with the string U. The range of valid code points for the Unicode standard is U0. U1. 0FFFF, inclusive, divided in 1. Characters in the range U0. UFFFF are in the plane 0, called the Basic Multilingual Plane BMP. This plane contains most commonly used characters. Characters in the range U1. U1. 0FFFF in the other planes are called supplementary characters. The following table shows examples of code point values Character. Unicode code point. Glyph. Latin AU0. Latin sharp SU0. DFHan for East. Autocar India Magazine Pdf. U6. Ampersand. U0. Inverted exclamation mark. U0. 0A1Section sign. U0. 0A7A code point is represented by a sequence of code units. The mapping is defined by the encoding. Thus, the number of code units required to represent a code point depends on the encoding UTF 8 code points map to a sequence of one, two, three or four code units. UTF 1. 6 code units are twice as long as 8 bit code units. Therefore, any code point with a scalar value less than U1. Code points with a value U1. These pairs of code units have a unique term in UTF 1. Unicode surrogate pairs. UTF 3. 2 the 3. GB1. Code points are mapped to one, two, or four code units. Unicode encoding modeleditUnicode and its parallel standard, the ISOIEC 1. Universal Character Set, together constitute a modern, unified character encoding. Rather than mapping characters directly to octets bytes, they separately define what characters are available, corresponding natural numbers code points, how those numbers are encoded as a series of fixed size natural numbers code units, and finally how those units are encoded as a stream of octets. The purpose of this decomposition is to establish a universal set of characters that can be encoded in a variety of ways. To describe this model correctly requires more precise terms than character set and character encoding. The terms used in the modern model follow 4A character repertoire is the full set of abstract characters that a system supports. The repertoire may be closed, i. ASCII and most of the ISO 8. Unicode and to a limited extent the Windows code pages. Online ebook PDF converter. Online ebook converter. Convert your text to the PDF format optimized for ebooks with this free online ebook converter. Many ebook reader understand the PDF format. Select the target ebook reader to further optimize the PDF file for the size of your device. The converter supports almost 2. Our ebook converter accepts a variety of input formats. You can do ebook convertions for example from TXT to PDF, HTML to PDF, e. Pub to PDF, mobi to PDF, OEB to PDF, RTF to PDF and many more. Just try and if it does not work for your specific document, let us know.